The Virtual Any Cloud Network Vision

The network of the future is software-defined. A Virtual Cloud Network, built on VMware NSX technology, is a software layer from on-prem data center to any cloud, any branch and any infrastructure.
VMware NSX is the foundation of the Virtual Cloud Network which consists of : NSX Data Center, NSX Cloud, App Defense , NSX SD-WAN by VeloCloud and NSX Hybrid Connect.
In this blog, I will be focusing on NSX Cloud piece of it to demonstrate its key features and benefits.
NSX Cloud
NSX Cloud is a secure, consistent foundation that makes managing the networking and security of your workloads living literally on any cloud which includes your on-prem private cloud and/or the hyper-scale public clouds (AWS, Azure and GCP).
It solves challenges Cloud Architects face when dealing with public clouds which include Lack of real-time visibility in cloud traffic flows, security policy consistency across hybrid clouds, compliance to enterprise security policies and leveraging existing operational tools.
It also adds a new line of revenue for Cloud Service Providers where NSX Cloud can be utilized to offer managed security services for their tenants’ workloads living on any cloud.
So What Are The Benefits of NSX Cloud in The Virtual Cloud Network?
1. Consistent Security For Apps Running On Any Cloud:
The main benefit in my opinion when utilizing NSX Cloud is the ability to enforce your Firewall security rules from your on-prem NSX Manager to workloads living on-premise and/or Azure and/or AWS and/or Google Cloud Platform using the same firewall rule applied across all clouds.
NSX Cloud brings networking and security capabilities to endpoints across multiple clouds. By integrating with NSX Data Center (deployed on-premises), it enables networking and security management across clouds and data center sites using the same NSX manager deployed on-prem.
Security policy is automatically applied and enforced based on instance attributes and user-defined tags. Policies automatically follow instances when they are moved within and across clouds.Dynamic Policies can based on
- VM attributes in cloud – eg VNET ID, Region, Name, Resource Group, etc
- Customer defined Cloud resource tags

Example:
A 3-tier application (Web VMs / App VMs/ DB VMs) consists of :
- Multiple Web servers spread across multiple hyperscale clouds: AWS/Azure/GCP. All of these servers will be tagged its respective native cloud tags: “Web”
- App server is a kubernetes container living On-Premises and will be tagged with “App”
- DB Server which consists of multiple VMs living On-Premises and will be tagged with “DB”
All of the above 3 tier app workloads will be tagged with a unique tag that will differentiate the application (in this case FE/APP/DB of website X). We will be using this tag to apply-to field in the DFW rules.
Webservers will need to to communicate with App servers living on AWS on port TCP 8443.
App containers would need to communicate with the DB servers on port MySQL TCP 3306.
Any should be able to communicate with the Web Servers on HTTPS TCP 443.
3 Firewall rules will be needed from the NSX Manager living on-prem that will enforce the above security posture using security tags constructs across ALL of the leveraged clouds.

2. Manageability and Visibility Across All Public Clouds
From the NSX Cloud Service Manager “CSM”, you will have the option to add all your Public Cloud accounts (AWS/Azure/GCP).
Once you add all your public cloud accounts, you will be able to view all of the Accounts, Regions, VPCs/VNETs you own along with their respective workloads from the same User Interface. Think of its a single pane of glass across all accounts across Public Clouds.

This will simplify the manageability of your workloads and save a lot of time in troubleshooting and capacity planning.

3. Real Time Operation Monitoring With DFW Syslog and L3SPAN in Public Clouds
From an operational perspective, you want to make sure all these security groups that you have are active and on. Since the Firewall and Security policies are now managed via the NSX manager, we will have the option to use syslog which look very similar to the logs created by hypervisor.
You can collect the data and send it to your Syslog collector, say Splunk and you will be able to run Data Analysis off of it.
This will provide statistics on who are the VMs talking to , what ports are permitted/denied etc.

Real Time Operations visibility can also be complimented by using the L3SPAN in public clouds per the below flow:
- Enable NSX L3 SPAN/Mirror on a per Logical port or Logical switch basis using Port-mirroring Switching Profile
- NSX Agent running inside the VM captures the traffic.
- Mirrored traffic forwarded to IP destination (collector) within VPC using GRE

4. Full Security Compliance with the Quarantine Option
You will have the option for full compliance for policy enforcement where the VMs that are created in the public cloud which are not managed by NSX will be quarantined.
This is done via the Multi-layered security which provides two independent security perimeters, primary security through NSX firewall, second layer of security through the native public cloud security groups which will be utilized by the NSX.
Note– This is optional. You can still have a dev environment that has both NSX managed and non managed workloads without enforcing the quarantine.

Note: As of the publishing date of this blog, the NSX-T 2.2 GA version fully supports workloads on-prem and Azure.
The upcoming NSX-T Cloud versions will be supporting AWS and other public Clouds.
In Summary
The virtual any cloud network is the next generation of cloud Networking. Cloud Admins could now utilize NSX Cloud to have full visibility for cloud traffic flows while the Security admins will enforce consistent security policies across all clouds.
Cloud Service Providers can utilize NSX Cloud to offer managed services for their tenant workloads anywhere, creating a new line of revenue.
In my next post, I will discuss the CSM in further details along with deep diving on the architecture of NSX Cloud.

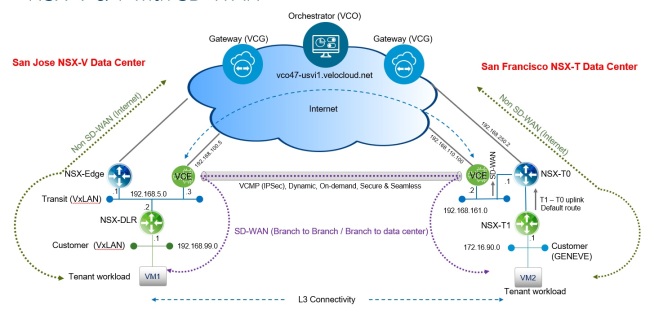












 Logical networking and security across multiple vCenters allow for the ability to access and pool resources form multiple vCenter domains. Resources are no longer isolated based on vCenter and/or vCD boundaries which hence allows the ability to access and pool resources form multiple vCenter domains achieving better utilization and less idle hosts.
Logical networking and security across multiple vCenters allow for the ability to access and pool resources form multiple vCenter domains. Resources are no longer isolated based on vCenter and/or vCD boundaries which hence allows the ability to access and pool resources form multiple vCenter domains achieving better utilization and less idle hosts.